XML与古籍电子化
作者:王晓波
1.XML简介
XML(Extensible Markup Language)是介于HTML和SGML中间的语言。比HTML具有更强的描述能力,但比SGML更简单。
HTML(Hypertext Markup Language)用于描述一个文件的显示,并且提供了文件间的联接,更主要的是它的简单性,极大地推动了因特网的发展。但是随着HTML的广泛使用,它的缺点也就不断涌现出来:
(1)由于各个浏览器的制造厂商为了抢占市场份额,纷纷推出自己的HTML标准,使得HTML互相不兼容。构造要想在各个浏览器上都正确显示的HTML,并不是很容易。
(2)由于浏览器的“宽容”,致使许多文件表面显示正确,但并不符合语言规范。
(3)HTML是为了描述数据表示的,它并不关心内容的含义,在以下HTML片断中,<H1>史记</H1>,<H2>司马迁</H2>。
无法区分“史记”和“司马迁”有什么含义上的不同,它只表示两者显示方式不一样。
(4)HTML的标记是由浏览器厂商提供的,用户无法自己定义来描述自己的数据。
第(2)、(3)两条使得构造智能的搜索引擎及其它的高层应用变得很困难,因而人们也更难于在因特网浩如烟海的数据中搜导信息。时代的需要促使人们开发新的“因特网语言”,但它一定要充分吸收HTML的成功之处。
SGML(Standard General Markup Language )是用于描述数据的语言,其中有许多特性,但是非常复杂。SGML标准已存在很多年了,但由于构造基于SGML的应用程序相当困难,大大地限制了SGML的发展。
实际需要推动了XML的发展,XML是一种元语言,只是用于定义一组标记,这一组标记,就可以用来描述数据,形成一种特定的标记语言。用户可以自己定义标记,这就有了极大的灵活性。
如:
<Book>
<TITLE> 史记 </TITLE>
<AUTHOR> 司马迁 </ AUTHOR>
</ Book>
这比上面的HTML语言片断含义清晰了。而且应用程序有可能智能的处理这些数据。如果在某个特定领域定义XML标记语言,那么信息交换就容易多了。
现在已定义了许多行业的XML语言,如用于描述化学分子式的CML(Chemical Markup Language),用于描述数学公式的MathML(Mathematics Markup Language),用于描述多媒体的SMIL(Synchronized Multimedia Intergraded Language)等等,这都给信息交换和信息挖掘提供了坚实的基础。
XML的特性:
(1)可直接应用于因特网。有两种方式使用XML:
其一在Web Server上有一个XML处理程序,在XML被请求时,将其转化为HTML发送给客户端。其二如果用户的浏览器支持XML的那只需在XML文档中加入一个描述XML各元素的显示特性的XSL(Extensible Stylesheet Language),用户浏览器即可直接显示。
(2)可支持多种应用。XML的应用领域不断拓宽,已从简单网络语言,进入到各个领域(如将代替EDI为e-commerce提供强大动力。又如,可能成为RPC低层通信的数据表示标准),并且为这些领域带来新的动力。
(3)易于处理。它不允许递归定义,只是简单的树形结构,因而构造基于XML的程序相对来说容易的多,而且如果有了XML分析器后,就不必每定义一组标记就写一个程序来分析这些数据。
(4)可以验证XML是否是符合规范。
XML分为两种:一种称为well-formed,只要是完全嵌套的文档,没有交错,又符合一些基本的定义,就可以称为well-formed。另一种称为valid,首先必须是文档,是well-formed,而且其它标记要完全符合DTD(文档类型定义),才能称得上valid。
正相当于编译器对于变成语言的重要性一样。由于XML的可验证性,可以将许多文档的错误轻易派出,这对于拥有大量数据处理的电子化领域,简直是太重要了。
以上说明XML是描述数据的,那么用户如何阅读XML文件呢?其关键是另一个语言XSL(Extensible Stylesheet Language),基于模版匹配,XSL可以访到源XML中的任何标记,然后生成结果文档,他不象CSS一样,只是简单的将某个标记定义一种显示属性,还可以依据结点的上下文,对源XML进行排序,筛选等处理后在写入结果文档。XSL可以将XML映射到HTML,也可以将XML映射到某种页面描述语言。这种将数据与数据的显示分离的优点是一个数据可以使用不同的方式去显示。
2.XML对古籍电子化的意义
2.1 XML易于表达数据
古籍电子化的结果不应该只是一堆字符,其最终目的是:“更加有效利用信息”,首先是要求在日益发展的因特网上访问数据,因而要求所生成的内容要易于在因特网上发布;其次是如何找到所需信息,解决方案是采用全文检索技术。如何阅读所需信息,最好的解决办法是原样复原,即在电子化的过程中保存源版面信息,真正需要的时候再排版出来。
下图为原书最普通的一页:

图3.1 数据描述示例图
如何表示上述数据呢?如果用数据库来表示其信息,那会是非常困难的工作。因为数据库适宜于处理这样的数据,对同一个表中的列来说,他们之间的顺序不具有重要的含义,即行之间不存直接的联系。例如简单按类型将其分别字符表和图像表,每个字和图作为一行来表示,将所有的属性都记录下来则其间的内在联系就必须通过计算获得。
另一种方案是自己定义结构。这种方式可以定义任意结构,处理任何数据。但是这种方案最大的缺点就是不易扩充,伸缩性不好。比如在制作的过程中发现某个字不是已编码汉字,那么正常的表现方式是,显示一个方框“□”,当鼠标移至该字时,能够显示该字的原图,对于自己定义的结构来说,改变起来并不是很容易的事情。请见如下两页内容:
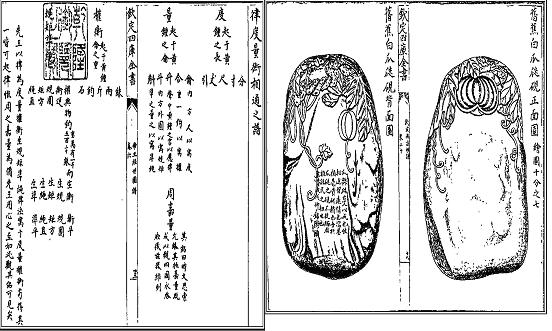
图3.2 复杂数据示意图
原有的数据结构不再适应这有表和图的结构,那么需要重新扩充原有的设计,而且所有的处理程序都必须改写,对于数据纷繁复杂的电子化来说这种工作量是巨大的。
现在有了XML,这种问题就相对容易,这几页内容可以用以下XML片断来表示。
<book>
<bookname>五礼通考</bookname>
<author>……<author>
<author>……<author> //可以由多个作者
<page pageno=”2”>
<col colno=”1”>
<section sectiontype=”BIGWORD” startrow=”2”>也</section>
</col>
<col>
<section sectiontype=”RIGHTSMALL” startrow=”2”>何氏楷曰太白名號甚多……廣如</section> <section>……</section>
</col>
……
<section sectiontype=”BIGWORD” startrow=”1”>郑风女曰<Ucode src=”*******.bmp”/>鸣子……</section>
</page>
<page pageno=”43”>
<table> <tr>
<table>
<tr>庆</tr>
<tr>起于黄钟之长</tr> //可以在<tr>中加入字排列的属性
<tr>分寸尺犬引</tr>
</table>
</tr></table>
</page>
<page pageno=”18”>
<image src=”******.bmp”>
<title><ucode src=“******.bmp”/>蕉白瓜<ucode src=”******.bmp” />砚正面图< section sectiontype=”RIGHTSMALLWORD” >绘图十分之七</section>
</title>
</image>
<image src=”******.bmp” />
<page>
</book>
由以上的表示可以看出XML表达能力时非常强大的,而且易于扩充。
2.2用XML可以便于处理数据
利用XML可以极大地减少软件开发的成本。这种情况不仅仅出现在电子化的结果上,在电子化的流程中,需要各式各样的文件,定义各种结构。对于每一个文件,都必须有一个生成的模块,分析的模块,不仅软件开发成本加大,而且对于数据的正确性缺乏验证,XML恰好解决了这个问题。
就以前面的版面校对为例。版面校对算得上经过认真设计的软件,它吸收了许多其它软件提出的概念,如从解释器里吸收了指令的概念,从数据库里吸收了日志文件的概念,指令的设计又受了标记语言的粗浅影响,它也的确表现得不错。
现在如果重新做这个软件,会采用一个新的方式:
① 用XML表示数据。
② 用XSL表示指令和指令集文件。
③ 编辑的过程相当于用XSL文件对XML处理。
④ 版面校对只须处理XML文件即可。
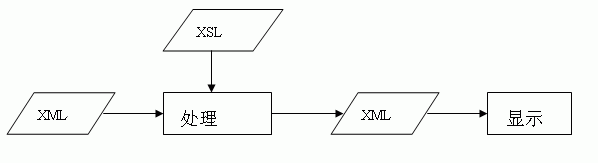
图3.3 软件结构示意图
2.3 XML便于显示和使用数据
对于电子化后的信息,可能有不同的使用方式,例如:可能在因特网上公布,可能打印成册出售,等等。利用XML可以非常容易做到。
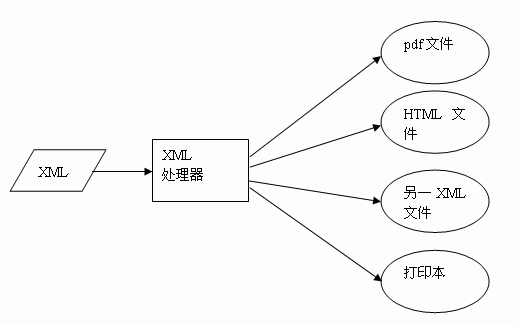
而且这种XML处理器不是为特定项目而开发的,而且有现成的共享软件,不需要程序员自己开发。并且随着这种共享软件功能发展,这种开发模式将更加流行。
3.e-Publishing Server
上面已经论述了XML易于电子化数据的表示,处理和显示,但对于海量数据来说,XML作为一种文本流,显然处理效率不高,将XML与数据库有机结合起来,将大大方便电子化工作。由于现有的数据库缺乏对XML的支持,而且缺少对中文古籍电子化至关重要的汉字关联特性的支持。这是我开发e-Publishing Server的动机。
3.1 e-Publishing Server的特性
(1)为适应电子出版物而开发,只支持静态数据,无需锁定机制因而效率极高。
(2)支持UNICODE。
(3)支持XML,因而接口非常简单。
(4)内建多种索引,建立索引易如反掌,且查询效率极高。
(5)内建汉字关联字表和汉字属性库,特别适合中文电子出版物。
(6)内建全文检索。
3.2 e-Publishing Server的结构图
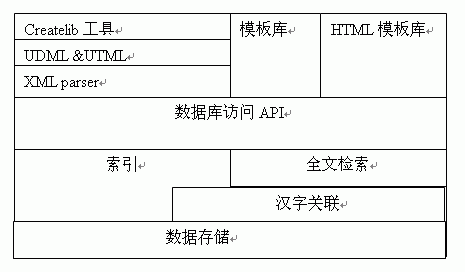
图3.5 e-Pubishing server 结构图
3.3 UDML
(1)语言定义
UDML是描述e-Publish Server的库XML。
(2)UDML
UDML完全遵循XML1.0规范(请见W3C的Extensible Markup Language (XML) 1.0规范)。因而UDML对大小写是敏感的。UDML非常简单,仅包含数据库的名字和该库包含的表的信息。
下面是一个简单的例子:
<? xml version = ”1.0” standalone =”no” encoding =”UTF-16” ?>
<! DOCTYPE database SYSTEM “database.dtd” >
<database dbname =”whtz” description = “中华文化通志”>
< table tablename = “content” description =”书籍内容”
source =”content.xml” />
< table tablename =”dian” description = “典”
source =”dian.xml” />
……
< table tablename =”jie” description =”节” source =”jie. xml” />
</ database>
UDML的处理程序将根据以上xml文件建立一个数据库,并依次将各个表装入数据库中。
(3.)UDML的DTD
<! ELEMENT database ( table) * >
<! ATTLIST database
dbname NMTOKEN # REQUIRED
description PCDATA # REQUIRED
>
<! ATTLIST table
tablename NMTOKEN # REQUIRED
description PCDATA #REQUIRED
source PCDATA #REQUIRED
>
3.4 UTML
(1)语言定义
UTML是描述e-Publishing Server的表的XML。
(2)UTML简介
UTML完全遵循XML1.0规范(请见W3C的Extensible Markup Language (XML)1.0规范)。因而UTML对大小写是敏感的。
UTML完全描述了一个表的结构和它包含的数据,由以下几个部分组成,表的名称,表的模式,表的数据。
下面是一个简单的例子:
<? xml version =”1.0” standalone =”no” encoding =”UTF-16” ?>
<!DOCTYPE table SYSTEM “table.dtd” >
< table tablename= “content” description =”文化通志书籍内容”>
< schema Column- number =”3” >
< column_schema column_name =”jie_id” column-no =”1” description =”节标识符” type =”INTERGER” key=1 indextype =”sort” / >
< column-schema column_name =”jie-content” column-no =”3” description =”一节内容” type =”WSTRING” indextype =”ftr” / >
</ schema >
< data >
< ROW row_no =”1”>
< field field_no =”1”>1008031115 </ field>
<field field_no =”2” >唐代文化</ field >
< field field_no =”3”>唐太宗李世民……< skip > …< / skip > < image width =”200” height =”100” type =”BMP” alternate =”唐太宗李世民画像” title =”唐太宗” source =”S1500.bmp” />
…… < / field >
< /ROW>
……
< ROW row_no = “1500” >……</ ROW>
< / data >
</ table >
根据列的类型,有的列只能包含简单的内容,如一个普通字符串,有的列可以包含更复杂的内容,如为一段XML。
可以包含< skip>,用于指明其元素内容不进全文检索库,并且UTML的处理程序在存储该内容的时候将忽略它。
也可以包含< image / >,用于在XML中嵌入一幅图。UTML的处理程序在处理该元素的时候,将source标识的文件装入数据库,并且可能改变该元素,如去掉属性source,而添加属性id,表示该图在数据库中的标识。
输入的xml还可以包含emphasize>,以指明全文检索的匹配结果,以便于客户程序加亮显示。
由此可见,由于引入了XML,使得数据库每列内容及可以是预定类型,又可以是具有结构的XML,大大简化了表的结构。有时在传统的关系性数据库中十几个表来表示的数据可以仅需一、二个包含XML的表即可表达清楚,特别是那些不用于做检索条件的字段,即使可能需要检索,如果辅以XML的处理程序,也是完全可以做到的。
(3)UTML的DTD
<!ELEMENT table ( schema, data ) >
<!ATTLIST table
tablename NMTOKEN #REQUIRED
description CDATA #REQUIRED
>
<!ELEMENT schema ( column_schema )+ >
<!ATTLIST schema
column_number CDATA #REQUIRED>
<!ELEMENT column_schema EMPTY >
<!ATTLIST column_schema
column_name CDATA #REQUIRED
column_no CDATA #REQUIRED
description CDATA #REQUIRED
type ( DWORD| WCHAR | WSTRING | IMAGE | XML ) "WSTRING"
key (YES | NO) "NO"
indextype ( NONE | SORT | KEYSORT | KEY | FTR ) "NONE"
>
<!ELEMENT data ( row )* >
<!ELEMENT row ( field )* >
<!ATTLIST row
row_no CDATA #REQUIRED
>
<!ELEMENT field ( #PCDATA | para )* >
<!ATTLIST field
no CDATA #REQUIRED
>
<!ELEMENT para (#PCDATA|note|image|sub|sup|tbl|skip|emphersize)* >
<!ELEMENT note (#PCDATA|image|sup|sub)*>
<!ELEMENT image EMPTY>
<!ATTLIST image
inline (yes|no) "yes"
src CDATA #REQUIRED
id CDATA #REQUIRED
alt CDATA #IMPLIED>
<!ELEMENT sub ( #PCDATA ) >
<!ELEMENT sup ( #PCDATA ) >
<!ELEMENT tbl (tr)+>
<!ELEMENT tr (td)+>
<!ELEMENT td (#PCDATA|note|sub|sup|image|skip|emphersize)*>
<!ELEMENT emphersize (#PCDATA | skip )* >
<!ELEMENT skip (#PCDATA | image | note )* >